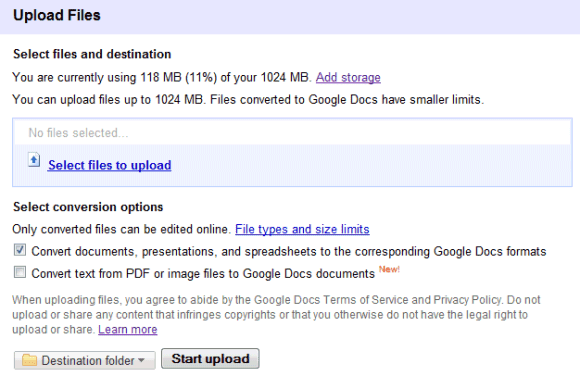
I've tried to convert an excerpt from the book Rework and the result wasn't great. About 10% of the text has been incorrectly converted and the formatting hasn't been preserved.
"This document contains text automatically extracted from a PDF or image file. Formatting may have been lost and not all text may have been recognized," explained Google in a note included in the document.
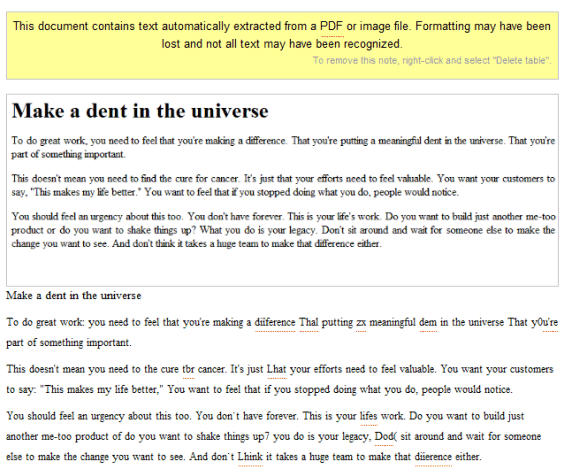
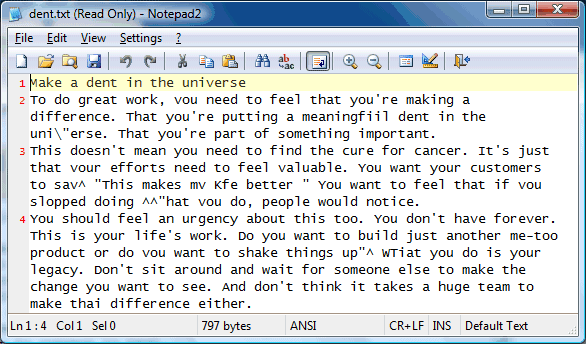
To be fair, ABBYY Online wasn't able to produce much better results:
Update: Google Docs Blog says that this feature only works for the following languages: English, French, Italian, German and Spanish. "For the technically curious: we're using Optical Character Recognition (OCR) that our friends from Google Books helped us set up. OCR works best with high-resolution images, and not all formatting may be preserved."
{ spotted by George }
No comments:
Post a Comment